Accessing IEEE 7000 standard is hostile to User
published:
by Harshvardhan J. Pandit
is part of: Rants
ethics standardisation
The IEEE 7000:2021 is a standard which describes a "Model Process for Addressing Ethical Concerns during System Design". As such, it is an important publication for the current times where ethical concerns and norms are required to be increasingly considered at all stages of technology development and application. IEEE touts this standard as "free" for anyone to access and use. However, in reality, the entire experience of trying to access the standard document was incredibly frustrating and user-hostile.
Account Required for Accessing Document
To access this "free" standard from the "reading room", you need to either have a subscription through your university or an account with IEEE. My university has a subscription to access all of IEEE's published articles for conferences and journals, but still it does not have access. This leaves creating an account, which is free, except you will be paying with your privacy. Not as bad as the worst websites, but there are still trackers and fingerprinting mechanisms without valid consent or legitimate interest in place. Still okay, not a big deal, we're giving privacy away like free candy on the internet anyway. I used a free temp email service to get a random email address and used that to sign up.
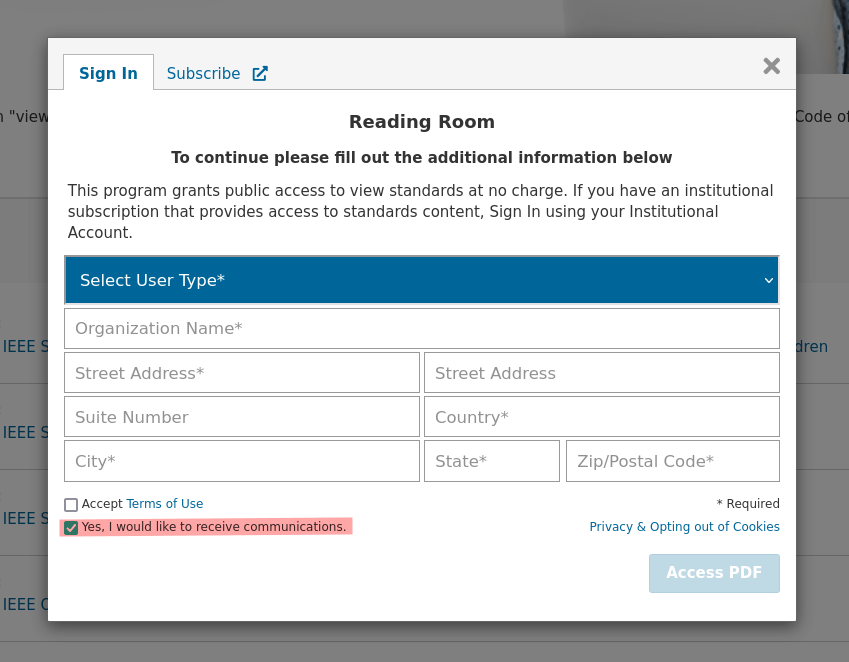
Document access is user-hostile
Once you are able to access the document, you will find options to either read it online or pay to buy a PDF which you can download. Now this isn't the worst model, at least the document is available for reading without paying even if its only online. Compared to ISO standards, which aren't even accessible, this is still a better model.
Moving on, let's get to the fun parts. When you load the document, you realise you can only see one page. This is because the reader application will load a single page at a time. Always. Even if you refresh the page, it goes back to displaying a single page and forces you to click again and again to proceed. Each page is downloaded as a high-res image, which means that every time you want to go to the next page, it takes a couple of seconds to load every single page. For a document with about 80 pages, you'll be wasting entire minutes just browsing from the start to the end. What a crappy and user-hostile design.

In addition to the absurd way pages are loaded, they are loaded as images. Which means no text selection, no searching functionality, no printing (reliably), or any of the several other conveniences text on screen offers. Want to search something elsewhere in the document but don't know what page number it is on? Tough luck. Want links to jump between sections or to external references? Images cannot do that! Oh, and printing is disabled so you cannot print a document once all pages are completely loaded.
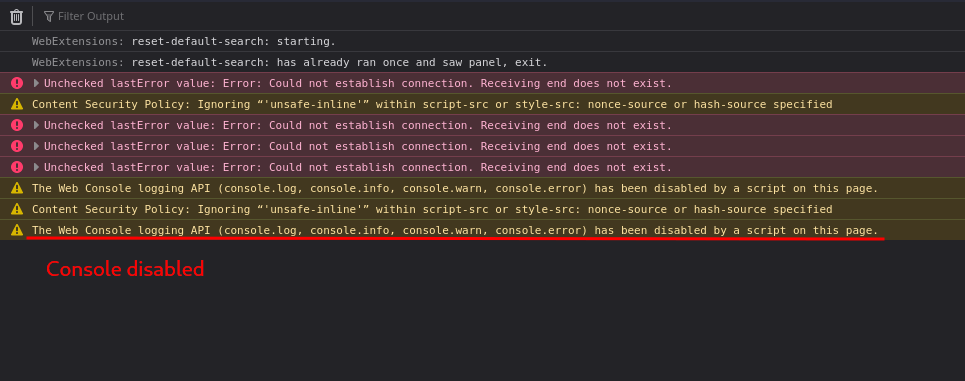
If you know a little bit about how web pages work and that browsers are amazing feats of engineering that can support all sorts of hacks to get things done - you'll have pressed the button to open the developer tools. Unfortunately, on Firefox for me, this caused an issue and the dev tools won't open. Right click was disabled, so I could not inspect the specific elements to figure out how to speed things up. Neither could I use the console, because I suspect the page had defined a global console variable that overrides the browser's. So many tiny little hurdles to keep the user away from having a better experience.
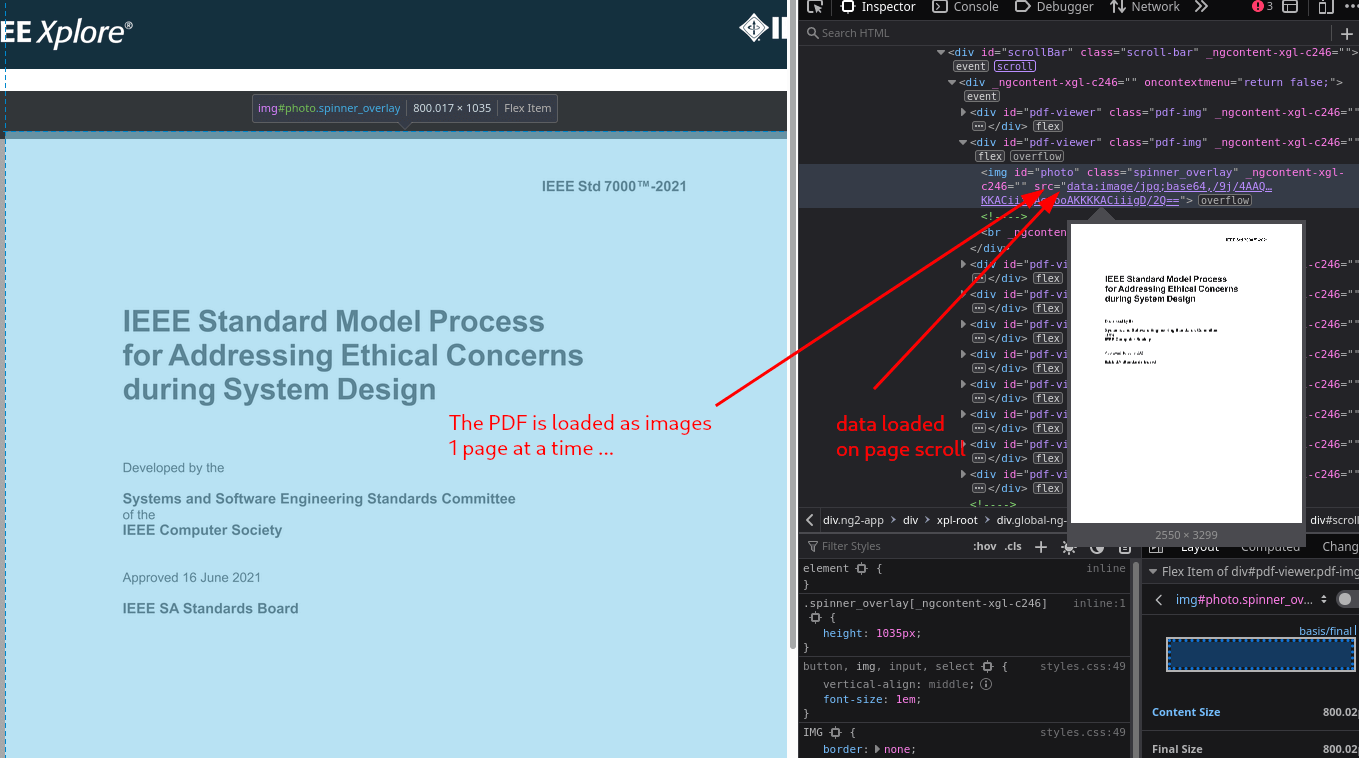
Writing a script to download the document in entirety
Now being fed up at the way in which I was actively disuaded from accessing and using that standards document, which talked about applied ethics and addressing concerns during design in a hypcritical turn of events, I was quite annoyed and frustrated. I could not resolve the images being downloaded instead of text, but I could try to speed up the download of images or make them more convenient, and more importantly - find a way to save the entire document.
The trick to open the developer tools and kick-start the console before any page disables or hijacks it - is to simly reload the page (disable cache if needed) and hit that F12 or whatever shortcut key is to open the console. Once the console has opened, it'll continue to function even if the page does weird stuff with the console variable. Once open, the developer tools can be used to inspect the page structure and events associated with how those pages are loaded one at a time, and what handlers are associated with them. This was feasible, but wasn't much better than manually clicking the button because the hold up was the downloading of images (classic I/O being the bottleneck issue).
Another more convenient way is to simply simulate what the human might do in such situations, which is clicking the next button to load the rest of the pages. However, doing this too quickly makes the pages load in the wrong order. So there has to be an artificial delay between one click and the next. And it has to be enough to guarantee that the pages load in order.
// set initial page count to pages loaded (will be 1)
var pages = $('#pdf-viewer > img').length;
// temp0 is obtained by using the element clicker
// and selecting the next page button
var rec_page_load = function() {
// if all pages have loaded,
// return without doing anything more
if (pages >= 86) { return; }
// more pages left to load
setTimeout(function() {
// check if any new pages have loaded
// by comparing page count with stored variable
// if new pages have loaded, increment counter
if ($('#pdf-viewer > img').length > pages) {
pages = pages + 1; }
temp0.click();
rec_page_load();
}, 3000);
}
rec_page_load();
Once the pages are loaded, using the developer tools to copy that DOM element/node containing the document pages (as images) and exporting them to another HTML file without the rest of the code is essential to print them into a PDF since the webpage blocks printing. This is interesting, because the total size of those pages is about 150MB. Not a lightweight document. Printing them in A4 size does reduce it to some extent, but to actually have a decent sized document, you can use image compression tools. Though these result in a loss of text readability.
In conclusion, I think all this was a waste of my time, of several people's time, without any respect for the users of these standards. What was ironic and made this more painful was the touting of this standard as "free" by all the people who have worked hard on this document over a significant period of time. To take that work, and to put it into such a user-hostile environment is unethical.