Creating A Vocabulary for Data Privacy
International Conference on Ontologies, DataBases, and Applications of Semantics (ODBASE)
✍ Harshvardhan J. Pandit* , Axel Polleres* , Bert Bos , Rob Brennan , Bud Bruegger , Fajar Ekaputra , Javier Fernandez , Ramisa Hamed , Elmar Kiesling , Mark Lizar , Eva Schlehahn , Simon Steyskal , Rigo Wenning
Description: Describes the creation of the DPV under the DPVCG
published version 🔓open-access archives: harshp.com , TARA , zenodo
📦resources: repo , Creating A Vocabulary for Data Privacy , DPV ontology
Abstract Managing privacy and understanding handling of personal data has turned into a fundamental right, at least within the European Union, with the General Data Protection Regulation (GDPR) being enforced since May 25\textsuperscript{th} 2018. This has led to tools and services that promise compliance to GDPR in terms of consent management and keeping track of personal data being processed. The information recorded within such tools, as well as that for compliance itself, needs to be interoperable to provide sufficient transparency in its usage. Additionally, interoperability is also necessary towards addressing the right to data portability under GDPR as well as creation of user-configurable and manageable privacy policies. We argue that such interoperability can be enabled through agreement over vocabularies using linked data principles. The W3C Data Privacy Vocabulary and Controls Community Group (DPVCG) was set up to jointly develop such vocabularies towards interoperability in the context of data privacy. This paper presents the resulting Data Privacy Vocabulary (DPV), along with a discussion on its potential uses, and an invitation for feedback and participation.
Keywords Privacy, GDPR, Interoperability, Semantic Web
Introduction
Concerns regarding privacy and trust have been raised to a point where regulators, citizens, and companies have started to take action. Services on the Web are often very complex orchestrations of co-operation between multiple actors, and the processing of personal data in Big Data environments is becoming more complex while being less transparent.
Yet, while from a legal point of view, the adoption of the General Data Protection Regulation (GDPR) [2] in April 2016, as well the California Consumer Privacy Act (CCPA) [3] of 2018 regulate processing of personal data, their technical implementation in operative IT systems is far from being standardised. While building privacy-by-design [4] into systems is a much wider scope, we lack the tools, standards, and best practices for those wanting to be good citizens of the Web to provide interoperable and understandable privacy controls, or to keep records of data processing in an accountable manner, with the possible exception of work on permissions [5] and tracking protection [6], but even those only cover partial aspects.
To this end, the work presented in this paper aims to set a basis for the establishment of interoperable standards in this domain. In particular, it addresses the following gaps by complementing existing (W3C) standards:
There are no standard vocabularies to describe and interchange personal data. Such vocabularies are relevant, for instance, to support data subjects’ right to data portability under Article 20 of the GDPR [2].
There are no agreed upon vocabularies or taxonomies for describing purposes of personal data handling and categories of processing: the GDPR requires legal bases for data processing, including consent, be tied to the specific purposes and processing of personal data to justify their lawful use. Consequently personal data processing should be logged with a standard reference to a purpose which complies with the norms set by the legal bases - such as the individual’s consent. The concrete taxonomies for representing this information in the context of personal data handling are not yet standardised.
There are no agreed upon vocabularies or ontologies that align the terminology of privacy legislations - such as the GDPR, to allow organisations to claim compliance with such regulations using machine-readable information.
The herein presented Data Privacy Vocabulary (DPV) aims at addressing these challenges by providing a comprehensive, standardized way set of terms for annotating provacy policies, consent receipts, and - in general - records of personal data handling. To this end, the rest of the paper is structured as follows: Section 2 explains the setup and governance of the DPV Community group within the World Wide Web Consortium (W3C) whereafter Section 3 summarizes pre-existing relevant vocabularies and standards that served as inputs. Section 4 describes the methodology that we applied in reconciling these towards the DPV vocabulary. The vocabulary itself and its modules are described in Section 5 (ommitting detailed descriptions of all classes and properties, which can be found in the published W3C CG draft at https://www.w3.org/ns/dpv). We close with a discussion of applications and adoption (Section 6) followed by conclusions and a call for participation and feedback (Section 7).
DPVCG: Data Privacy Vocabularies and Controls CG
To address the gaps mentioned in Section 1, a W3C workshop was announced1, which received 32 position statements and expressions of interest. These were used to create an agenda based on standards and solutions for interoperable privacy. The workshop took place on 17th and 18th April 2018 in Vienna and consisted of about 40 participants. Discussions and interactions were structured into sessions around the four themes of: (1) ‘relevant vocabularies and initiatives’, (2) ‘industry perspective’, (3) ‘research topics’, and (4) ‘governmental side and initiatives’. The workshop concluded with a discussion of the next steps and priorities in terms of standardisation and interoperability. The identified goals were (from highest to lowest priority): taxonomies for regulatory privacy terms (including GDPR), personal data, purposes, disclosure and consent (as well as other legal bases), details of anonymisation (and measures taken to protect personal data), and for recording logs of personal data processing.
Following this, a W3C Community Group (CG) with the title ‘Data Privacy Vocabularies and Controls CG’ (DPVCG) was formally established on 25th May 2018 - the implementation date of the GDPR. The group has a total of 55 participants to date representing academia, industry, legal experts, and other stakeholders. Its discussions are open via the public mailing list2, along with a wiki3 documenting meetings, resources, general information.
The CG had its first face-to-face meeting on 30th August 2018 co-located with the MyData 20184 conference at Helsinki, Finland. The goal of this meeting was agreement on the first steps and deliverables of the CG as well as establishment of meeting and management procedures. The outcome of this meeting was agreement on working towards the following deliverables:
Use cases and requirements: Collect and align common requirements from industry and stakeholders to identify areas where interoperability is needed in the handling of personal data. The outcome of this was a prioritised list of requirements to enable interoperability in the identified use-cases.
Alignment of vocabularies and identification of overlaps: Collect existing vocabularies and standardisation efforts, and identify their overlaps and suitability for covering the requirements prioritised in step one. The identified vocabularies are presented in Section 3.
Glossary of GDPR terms: An understandable and interoperable glossary of common terms from the GDPR and an analysis of how they are covered by the agreed vocabularies.
Vocabularies: Based on the heterogeneity or homogeneity of identified use-cases and requirements, create a set of (modular) vocabularies for exchanging and representing information in an interoperable form for personal data, purposes, processing, consent, anonymisation, and transparency logs. The resulting vocabulary is presented in Section 5.
A second face-to-face meeting was conducted on 3rd and 4th December 2019 at Vienna, Austria. The goal of this meeting was to analyse the collected use-cases and vocabularies, to establish agreement on the requirements for vocabularies to be delivered, and to plan ahead towards their conception and completion. A third face-to-face was organised on 4th and 5th April 2019 in Vienna and Dublin to finalise the vocabulary and reach an agreement towards the first public draft. The outcome of the meeting was agreement of terms used and its expression using RDF and OWL. The meeting also provided agreement over the namespace of the vocabulary, its hosting, and documentation. After over a year of collaborative effort, the CG published the ‘Data Privacy Vocabulary‘ (DPV) on 26th July 2019. The CG is currently welcoming feedback for DPV from the community and stakeholders in terms of comments, suggestions, and contributions.
Existing and Relevant Vocabularies
Existing relevant use cases and vocabularies were collected and documented in the wiki5 through individual submissions by CG members. The wiki page for each vocabulary presents a summary, its relevance, covered requirements, uptake, and applicable use-cases. Relevant terms were then identified from each vocabulary and categorised as per requirements. These were used as the basis for discussions regarding terms to be included and aligned in the DPV.
Existing Standards and Standardisation Efforts
The CG considered several web-relevant standards for terms relevant towards identified requirements: PROV-O [7] (and its extension P-Plan [8]) for provenance, ODRL [5] for expressing policies, vCard [9] for describing people and organisations, Activity Streams [10] for describing activities on the web, and Schema.org [11] for metadata used in description of web pages.
The CG also considered standardisation efforts undertaken by bodies relevant to the areas of privacy and interoperability. Classification of Everyday Living (COEL) [12] describes a privacy-by-design framework for the collection and processing of behavioural data with a focus on transparency and pseudo-anonymisation. It was developed by OASIS, which is a non-profit organisation dedicated to the development of open standards.
The ISA2 is a programme by the by the European Parliament and the Council of European Union for development of interoperable framework and solutions, which includes a set of vocabularies, termed ‘Core Vocabularies’ [13], for person, business, location, criterion and evidence, and public organisation. IEEE P7012 [14] is a work-in-progress effort to standardise privacy terms in a machine-readable manner for use and sharing on the web.
Consent Receipt [15] is an interoperable standard developed by the Kantara Initiative for capturing the consent given by a person regarding use of their personal data. The standard enables creation of receipts in human as well as machine readable formats for expressing information using pre-defined categories for personal data collection, purposes, and its use and disclosire. However, it does not address the requirements specified by the GDPR.
The Platform for Privacy Preferences Project (P3P) [16] is a (now-abandoned) protocol for websites to declare their intended use of personal data collection and usage with an emphasis on providing users with more control of their personal information when browsing the web. P3P provided a machine-readable vocabulary for websites and users to define their policies, which were then compared to determine privacy actions.
Vocabularies addressing Privacy and GDPR
The Scalable Policy-aware Linked Data Architecture For Privacy, Transparency and Compliance (SPECIAL) is an European h3020 project that uses semantic-web technologies in the expression and evaluation of information for GDPR compliance. SPECIAL has developed vocabularies for expressing Usage Policy [17] and Policy Log [18] in order to evaluate whether the recorded use of personal data is compliant with a given consent.
Mining and Reasoning with Legal Texts (MIREL) is another European h3020 project that uses semantic-web technologies for GDPR compliance. It has developed PrOnto (Privacy Ontology for Legal Reasoning) [19] - a legal ontology of concepts consisting of privacy agents, personal data types, processing operations, rights and obligations.
GDPRtEXT [20] provides a linked data version of the text of the GDPR that makes it possible for links to be established between information and the text of the GDPR by using RDF and OWL. It also provides a thesauri or vocabulary of concepts defined or referred to within the GDPR in a machine-readable manner using SKOS.
GDPRov [21] is an ontology to represent processes and activities associated with the lifecycle of personal data and consent as an abstract model or plan indicating what is supposed to happen, as well as the corresponding activity logs indicating things that have happened. It extends PROV-O and P-Plan with GDPR-specific terminology. GConsent [22] is an ontology for expressing necessary information for management and evaluating compliance of consent as governed by the obligations and requirements of the GDPR.
Considered ontologies developed prior to implementation of GDPR also include an ontology to express privacy preferences [23], a data protection ontology based on the GDPR [24], and an ontology for expressing consent [25].
Methodology
The process of vocabulary development was largely shaped by discussions and interactions between CG members, and was (informally) based on NeOn methodology scenarios [26]. The CG decided to work towards creating a generic or top-level vocabulary rather than restricting it to a particular domain or use-case in order to facilitate universal application and adoption. For this, existing work and approaches were analysed to identify terms relevant for describing specific categories of information, such as purposes of processing and personal data.
The analysis of existing vocabularies revealed a lack of top-level or abstract concepts necessary to provide an extendable mechanism for representing information in a hierarchical structure. Therefore, the CG decided to work towards creating a vocabulary that provided the necessary top-level concepts and relationships in a hierarchical structure. Agreement over categories of terms to be included in the vocabulary and relevance of existing terms was carried out through discussions, and documented in the wiki6.
While initially working towards a hierarchical taxonomy, the need for representing relationships and logic between terms led towards the creation of an ontology, with RDF/OWL being used to provide standardised serialisation. A base vocabulary was created based on the SPECIAL Usage Policy Language [17] to represent a policy, and additional terms were structured to extend them as modular (sub-)ontologies. Terms were then added in a top-down fashion, based on existing work or its identified absence.
Documentation of how terms were proposed, discussed, and added was recorded through a collaborative spreadsheet hosted on the Google Sheets platform7. The spreadsheet contained separate tabs for each ‘modular’ ontology and a base ontology representing combined their combined usage to represent personal data handling. The columns in the spreadsheet were mapped to semantic web representations, as depicted in Table 1. The vocabulary was created by using the Google Drive API in a script8 that extracted terms to create documentation of the taxonomy. This was then modified to generate RDF serialisations using rdflib9 as RDF/OWL was later adopted10. and documentation using ReSpec11. Plans for additions and changes to the vocabulary will follow a similar approach, where the proposal is documented and agreed upon through the public mailing list or CG meetings.
| Column Name | Description | Representation |
|---|---|---|
| Class/Property | If term is Class or Property | rdfs:Class|rdfs:Property |
| term | The IRI of the term | as IRI |
| description | Description or definition | dct:description |
| domain | Domain if it is a property | rdfs:domain |
| range | Range if it is a property | rdfs:range |
| super classes/properties | Parent classes or properties | rdfs:isSubClassOf |
| sub classes/properties | Child classes or properties | N/A |
| related terms | Terms relevant to this | rdfs:seeAlso |
| how related? | Nature of relation | use as is |
| comments | Comments used for discussion | N/A |
| source | The source of the term | rdfs:isDefinedBy |
| date | Date of creation | dct:created |
| status | Status e.g. accepted,proposed | sw:term_status |
| comments | Comments to be recorded | rdfs:comment |
| contributor | dc:creator | dct:creator |
| date-accepted | Date of acceptance | dct:date-accepted |
| resolution | Record e.g. minutes of meeting | as IRI |
Data Privacy Vocabulary
As a result of the process above, the ‘Data Privacy Vocabulary‘ (DPV) has been published on 26th July 2019 at the namespace http://w3.org/ns/dpv (for which we will use the prefix dpv:) as a public draft for feedback. The current vocabulary provides terms (classes and properties) to annotate and categorise instances of legally compliant personal data handling. In particular, DPV provides extensible concepts and relationships to describe the following components (which are elaborated in further sections):
Personal Data Categories
Purposes
Processing Categories
Technical and Organisational Measures
Legal Basis
Consent
Recipients, Data Controllers, Data Subjects
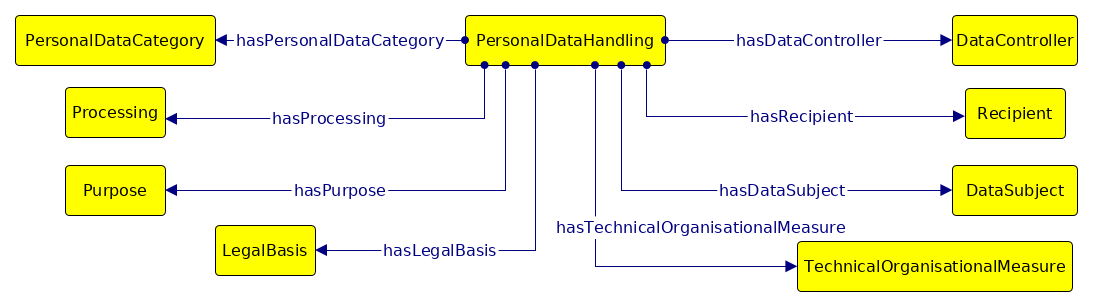
These terms are intended to express Personal Data Handling in a machine-readable form by specifying the personal data categories undergoing some processing, for some purpose, by data controller, justified by legal basis, with specific technical and organisational measures, which may result in data being shared with some recipient. The vocabulary is built up in a modular fashion, where each ‘module’ covers one of the above listed aspects, and which is linked together using a core Base Vocabulary.
Base Ontology
The ‘Base Ontology’ describes the top-level classes defining a policy for legal personal data handling. Classes and properties for each top-level class are further elaborated using sub-vocabularies, which are available as separate modules and are outlined in subsequent sections. While all concepts in DPV share a single dpv: namespace, the modular approach of providing the base ontology as a separate module makes it possible to use sub-vocabularies without the dpv:PersonalDataHandling class, for example to refer only to purposes. Exceptions to this are the NACE purpose taxonomy (cf. details Section 5.3) extending the dpv:Sector concept in the Purposes vocabulary, and the GDPR legal bases taxonomy (cf. details in Section [sec:dpv-legalbasis]) extending the top-level dpv:LegalBasis class - which are provided under a separate namespaces to indicate their specialisation. The core concepts of the Base Ontology module and their relationships are depicted in Figure 1.
Personal Data Categories
DPV provides broad top-level personal data categories adapted from the taxonomy provided by EnterPrivacy [27]. The top-level concepts in this taxonomy refer to the nature of information (financial, social, tracking) and to its inherent source (internal, external). Each top-level concept is represented in the DPV as a class, and is further elaborated by subclasses for referring to specific categories of information - such as preferences or demographics.
Regulations such as the GDPR allow information about personal data used in processing to be provided either as specific instances of persona data (e.g., “John Doe”) or as categories (e.g., name). Additionally, the class dpv:SpecialCategoryOfPersonalData represents categories that are ‘special’ or ‘sensitive’ and require additional conditions as per GDPR’s Article 9.
The categories defined in the personal data taxonomy can be used directly or further extended to refer to the scope of personal data used in processing. The taxonomy can be extended by subclassing the respective classes to depict specialised concepts, such as “likes regarding movies” or combined with classes to indicate specific contexts. The class dpv:DerivedPersonalData is one such context where information has been derived from existing information, e.g., inference of opinions from social media. Additional classes can be defined to specify contexts such as use of machine learning, accuracy, and source.
While the taxonomy is by no means exhaustive, the aim is to provide a sufficient coverage of abstract categories of personal data which can be extended using the subclass mechanism to represent concepts used in the real-world. For instance, Figure 2. shows the hierarchy of concepts for classifying depictions of individuals in pictures.
![Hierarchy of concepts for classifying depictions of individuals in pictures (inspired by EnterPrivacy [27])](img/032-personal-data-branch.png)
Purposes
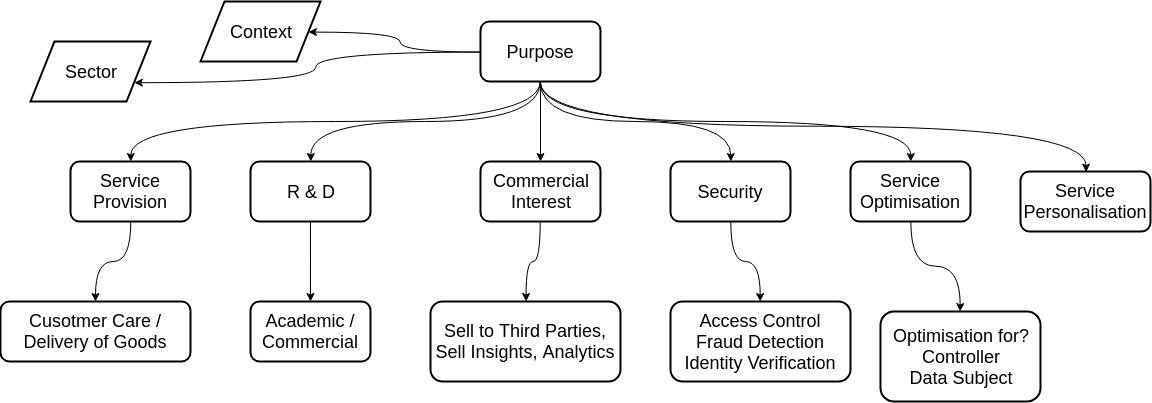
DPV at present defines a hierarchically (by subclassing) organized set of generic categories of data handling purposes, as depicted in Figure 3. Overall, DPV provides a list of 31 suggested purposes as subclasses of these generic purposes which may be extended as shown in Listing [lst:purpose-example] by further subclassing to create more specific ones. As regulations such as the GDPR generally require a specific purpose to be declared in an understandable manner, we suggest to such declare specific purposes as subclasses of one or several dpv:Purpose categories to make them as specific as possible, and to always annotate them with a human readable description (e.g., by using rdfs:label and rdfs:comment).
turtle :NewPurpose rdfs:subClassOf dpv:DeliveryOfGoods, dpv:FraudPreventionAndDetection ; rdfs:label "New Purpose" ; rdfs:comment "Intended delivery of goods with fraud prevention" .
Moreover, purposes can be further restricted to specific contexts using the class dpv:Context and the property dpv:hasContext. Similarly, DPVCG provides a way to restrict purposes to a specific business sector, i.e., allowing/restricting data handling to purposes related to particular business activities, using the class dpv:Sector and the property dpv:hasSector. Potential hierarchies for defining such business sectors include NACE12 (EU), NAICS13 (USA), ISIC14 (UN), and GICS15. At the moment, we recommend to use NACE (EU) codes using dpv-nace:NACE-CODE as shown in Listing [lst:purpose-example-nace], where the prefix dpv-nace: represents the DPV defined namespace http://www.w3.org/ns/dpv-nace#.
turtle :SomePurpose a dpv:Purpose ; rdfs:label "Some Purpose" ; dpv:hasSector dpv-nace:M72 .
Processing Categories
In this module, DPV provides a hierarchy of classes to specify operations associated with processing of personal data, which are required by regulations such as the GDPR. As common processing operations such as collect, share, and use have certain constraints or obligations in GDPR, it is necessary to accurately represent and define them for personal data handling. While the term ‘use’ is liberally used to refer to a broad range of processing categories in privacy notices, we recommend to select the most appropriate and specific terms to accurately reflect the nature of processing as applicable.
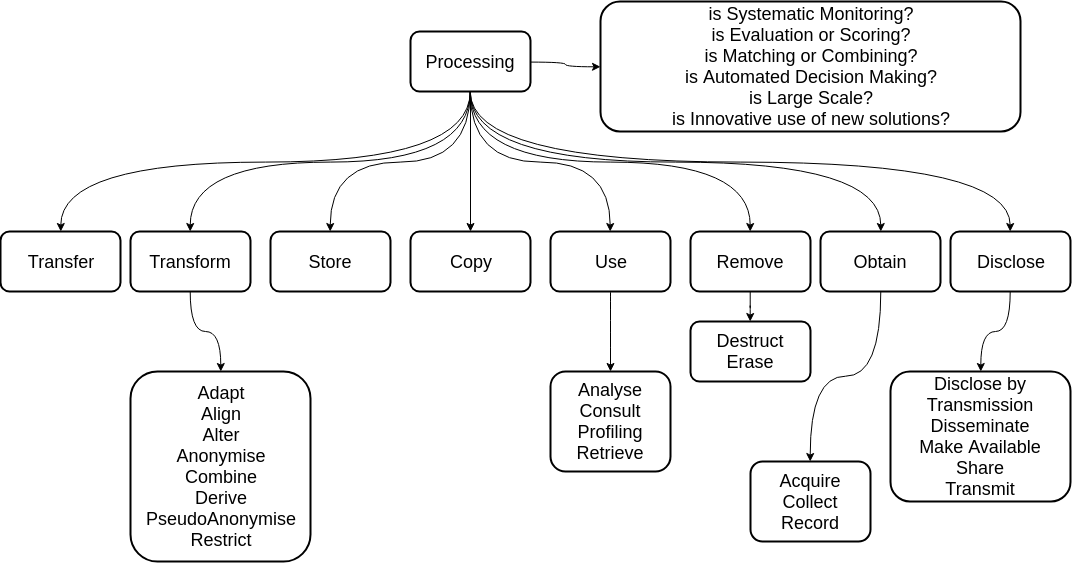
DPV defines top-level classes to represent the following broad categories of processing - Disclose, Copy, Obtain, Remove, Store, Transfer, Transform, and Use, as shown in Figure 4. Each of these are then again further expanded using subclasses to provide 33 processing categories, which includes terms defined in the definition of processing in GDPR (Article 4-2).
The DPVCG taxonomy further provides properties with a boolean range to indicate the nature of processing regarding Systematic Monitoring, Evaluation or Scoring, Automated Decision-Making, Matching or Combining, Large Scale processing, and Innovative use of new solutions, as these are relevant towards assessment of processing for GDPR compliance. [sec:dpv-processing]
Technical and Organisational Measures
Regulations require certain technical and organisational measures to be in place depending on the context of processing involving personal data. For example, GDPR (Article 32) states implementing appropriate measures by taking into account the state of the art, the costs of implementation and the nature, scope, context and purposes of processing, as well as risks, rights and freedoms. Examples of measures stated in the article states include:
the pseudonymisation and encryption of personal data
the ability to ensure the ongoing confidentiality, integrity, availability and resilience of processing systems and services
the ability to restore the availability and access to personal data in a timely manner in the event of a physical or technical incident
a process for regularly testing, assessing and evaluating the effectiveness of technical and organisational measures for ensuring the security of the processing
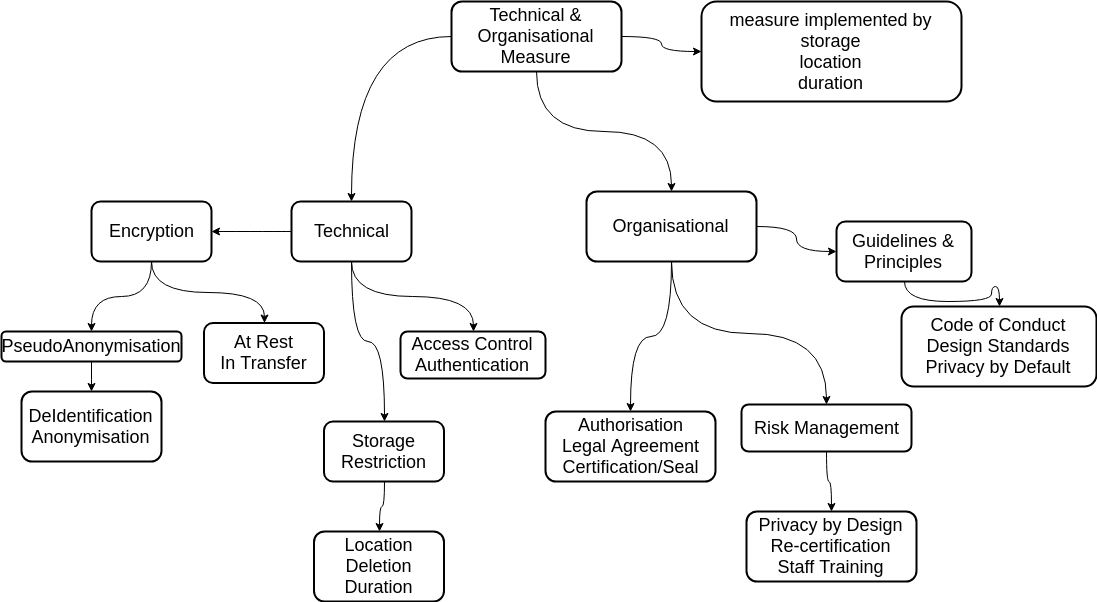
To address these requirements, DPV defines a module comprising of a hierarchical vocabulary for declaring such technical and organisational measures, as shown in Figure 5.
For any of the DPV declared measures, we provide a generic ObjectProperty (dpv:measureImplementedBy), and for the values of this attribute, we either allow a blank node with a single rdfs:comment to describe the measure, or a URI to a standard or best practice followed, i.e. a well-known identifier for that standard or a URL where the respective document describes the standard. The class StorageRestriction represents the measures used for storage of data with two specific properties provided for storage location and duration restrictions. While at the moment, we do not yet refer to specific certifications or security standards, in the future, we plan to provide a collection of URIs for identifying recommended standards and best practices, as they further develop. Feedback on adding specific ones to future versions of the DPV specification is particularly welcome.
[sec:dpv-measures]
Consent and other Legal Bases
While the vocabulary provides dpv:LegalBasis as a top-level concept representing the various legal bases that can be used for justifying processing of personal data, such legal bases may be defined differently in different legislations within the scope of legal jurisdictions. For the particular case of GDPR, we therefore provide the legal bases specific to GDPR as a separate aligned vocabulary, under the https://www.w3.org/ns/dpv-gdpr namespace (prefix: dpv-gdpr:).
This vocabulary defines the legal bases defined by Articles 6 and 9 of the GDPR, including consent, along with their description and source within. For example, dpv-gdpr:A6-1-b denotes the legal basis provided by fulfillement/performance of a contract.
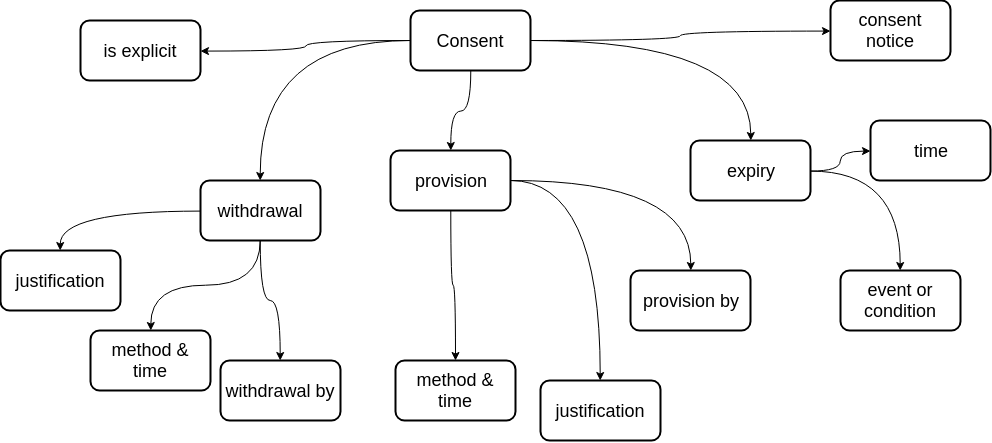
In addition to the legal bases, Consent is addressed with additional properties and classes within the core DPV vocabulary as it is a common form of legal justification across jurisdictions. The module describing consent, illustrated in Figure 6, provides the necessary terms to describe consent provision, withdrawal, and expiry. This is based on an analysis of existing work in the form of Consent Receipt [15] and GConsent [22].
[sec:dpv-legalbasis]
Recipients, Data Controllers, and Data Subjects
Last but not least, this module of the ontology is meant for defining a taxonomy of stakeholders involved in Personal DataHandling, extending the top level classes dpv:DataController, dpv:DataSubject, and dpv:Recipient from the Base vocabulary module. We consider defining recipients is important in the context of data privacy as it allows tracking the entities personal data is shared/transferred with. Similarly, a categorisation of Data Controllers and Data Subjects has bearing on the privacy of personal data handling, especially when considering situations such as where data subjects are children. The vocabulary currently provides only a few top-level classes to describe such recipients and data subjects, with an invitation to suggest/provide more terms for future releases:
dpv:Childas a subclass ofdpv:DataSubjectin order to capture policies and restrictions of data Handling related to children;dpv:Processoras a subclass ofdpv:Recipientto denote natural or legal persons, public authorities, agencies or other bodies which processes personal data on behalf of the controller;dpv:ThirdPartyas a subclass ofdpv:Recipientto provide a generic class for third party recipients, i.e. natural or legal persons, public authorities, agencies or bodies other than the data subject, controller, processor and persons who, under the direct authority of the controller or processor, are authorised to process personal data.
Potential Adoption and Usage
The primary aim of DPV is to assist in the representation of information concerning privacy in the context of personal data processing. To this end, it models concepts at an abstract or top-level to cover a broad range of concepts. This shall enable the DPV to be used as an domain-independent vocabulary which can be extended or specialised for specific domains or use-cases. Though the DPV does not define or restrict how such extension should be created, this section highlights some suggested methods for its adoption and usage.
Firstly, the modular nature of DPV enables adoption of a selected subset of the vocabulary only to address a specific use-case. For example, an adopter may only wish to utilise the concepts under Purpose and PersonalDataCategory without using/describing all aspects of a particular PersonalDataHandling from the base vocabulary.
In addition, the use of RDFS and OWL enables extending the DPV in a compatible manner to define domain-specific use-cases. For example, an extension targeting the finance domain can define additional concepts by using RDFS’ subclass mechanism. Such an extension, when represented as an ontology, will be compatible with the DPV, and will enable semantic interoperability of information, and ideally applications such as automated compliance checking for privacy policies and data handling records annotated with DPV and its extensions.
The DPV is intended to be used as an interoperable vocabulary where terms are structured in a hierarchy and have unambiguous definition to enable common agreement over their semantics. Such usage involves limiting the concepts to other pre-defined vocabulary, as seen in the case of Consent Receipts [15] and the SPECIAL vocabularies [18].
The SPECIAL project16 actually has demonstrated how the above-mentioned use case of automated compliance checking can be implemented based modeling privacy policies and log records of personal data handling in a manner compatible with DPV [28]. The SPECIAL project with its industry use case partners may also be viewed as a set of early adopters of the DPV, where currently further tools and a scalable architecture for transparent and accountable personal data processing in accordance with GDPR is being developed.
Conclusion
The Data Privacy Vocabulary is the outcome of cumulative effort of over a year in W3C’s Data Privacy Vocabulary and Controls Community Group (DPVCG). It represents the first step towards an effort to provide a standardised vocabulary to represent instances of legally compliant personal data handling. To this end, it provides a modular vocabulary representing concepts of personal data categories, purposes of processing, categories of processing, technical and organisational measures, legal bases, recipients, and consent.
With the onset of regulations in the privacy domain, the DPV fills an important gap by providing the necessary terms in an interoperable and extendable format. It is, to the best of our knowledge, currently the most comprehensive vocabulary regarding definition of privacy-related terms in addition to being aligned with regulations such as the GDPR, and attempting to comprehensively cover the relevant aspects of personal data handling. For continued development of this work, the DPVCG is currently inviting participation in the form of comments, feedback, and suggestions. Specifically, the DPVCG kindly requests proposals to extend its initial taxonomies by additional terms, where these are missing or need refinements in order to describe specific use cases of personal data handling.
Future plans also include producing documented examples of how the DPV could be adopted for further specific use-cases. Examples include annotating privacy policies, documenting information for specific laws such as GDPR, and producing transparent, machine-readable processing logs (for instance by mapping the DPV to existing database schemas and thereby generating/aggregating machine-readable transparency records directly out of their logging.
Acknowledgements We thank all members of the W3C DPVCG for their feedback and input to this work: a preliminary outline of the goals of CG has been presented in ISWC2018's SWSG workshop~\cite{bona-etal2018SW4SG} where we also gathered valuable feedback by the participants; this work is the first complete presentation of the resulting, proposed vocabulary elaborated by the DPVCG since. This work was supported by the European Union's Horizon 2020 research and innovation programme under grant 731601 (SPECIAL), by the Austrian Research Promotion Agency (FFG) under the projects ``EXPEDiTE'' and ``CitySpin'', by the ADAPT Centre for Digital Excellence funded by SFI Research Centres Programme (Grant 13/RC/2106), and co-funded by European Regional Development Fund.
References
[1] P. Bonatti et al., “Data privacy vocabularies and controls: Semantic web for transparency and privacy,” in Semantic web for social good workshop (swsg) co-located with iswc2018, 2018, vol. 2182 [Online]. Available: http://ceur-ws.org/Vol-2182/paper_3.pdf
[2] European Parliament and Council, “Regulation (EU) 2016/679 of the European Parliament and of the Council of 27 April 2016 on the protection of natural persons with regard to the processing of personal data and on the free movement of such data, and repealing Directive 95/46/EC (General Data Protection Regulation),” vol. 59. European Union, pp. 1–88, May-2016.
[4] A. Cavoukian and others, “Privacy by design: The 7 foundational principles,” Information and Privacy Commissioner of Ontario, Canada, vol. 5, 2009.
[5] R. Iannella and S. Villata, “ODRL Information Model 2.2,” ODRL Information Model 2.2. Feb-2018 [Online]. Available: https://www.w3.org/TR/odrl-model/. [Accessed: 19-Sep-2018]
[6] R. T. Fielding and D. Singer, “Tracking Preference Expression (DNT).” Jan-2019 [Online]. Available: https://www.w3.org/TR/tracking-dnt/. [Accessed: 24-Jul-2019]
[7] T. Lebo et al., “PROV-O: The PROV Ontology,” PROV-O: The PROV Ontology. 2013.
[8] D. Garijo and Y. Gil, “The P-PLAN Ontology,” The P-PLAN Ontology. Mar-2014 [Online]. Available: http://vocab.linkeddata.es/p-plan/. [Accessed: 19-Sep-2018]
[9] R. Iannella and J. McKinney, “vCard Ontology - for describing People and Organizations.” May-2014 [Online]. Available: https://www.w3.org/TR/vcard-rdf/. [Accessed: 23-Jul-2019]
[10] J. M. Snell and E. Prodromou, “Activity Streams 2.0.” May-2017 [Online]. Available: https://www.w3.org/TR/activitystreams-core/. [Accessed: 23-Jul-2019]
[13] Z. Aleksandrova, “Core Vocabularies,” ISA² - European Commission. Nov-2016 [Online]. Available: https://ec.europa.eu/isa2/solutions/core-vocabularies_en. [Accessed: 23-Jul-2019]
[15] M. Lizar and D. Turner, “Consent Receipt Specification v1.1.0,” Kantara Initiative, 2017 [Online]. Available: https://docs.kantarainitiative.org/cis/consent-receipt-specification-v1-1-0.pdf
[17] P. A. Bonatti, S. Kirrane, I. M. Petrova, L. Sauro, and E. Schlehahn, “The SPECIAL Usage Policy Language, V0.1,” 2018 [Online]. Available: https://www.specialprivacy.eu/vocabs
[18] B. A. Bonatti, W. Dullaert, J. D. Fernandez, S. Kirrane, U. Milosevic, and A. Polleres, “The SPECIAL Policy Log Vocabulary.” Nov-2018 [Online]. Available: https://aic.ai.wu.ac.at/qadlod/policyLog/. [Accessed: 23-Jul-2019]
[19] M. Palmirani, M. Martoni, A. Rossi, C. Bartolini, and L. Robaldo, “PrOnto: Privacy Ontology for Legal Reasoning,” in Electronic Government and the Information Systems Perspective, 2018, pp. 139–152.
[20] H. J. Pandit, K. Fatema, D. O’Sullivan, and D. Lewis, “GDPRtEXT - GDPR as a Linked Data Resource,” in The Semantic Web - European Semantic Web Conference, 2018, pp. 481–495, doi: 10/c3n4 [Online]. Available: https://link.springer.com/chapter/10.1007/978-3-319-93417-4_31. [Accessed: 17-Jun-2018]
[21] H. J. Pandit and D. Lewis, “Modelling Provenance for GDPR Compliance using Linked Open Data Vocabularies,” in Proceedings of the 5th Workshop on Society, Privacy and the Semantic Web - Policy and Technology (PrivOn2017) (PrivOn), 2017 [Online]. Available: http://ceur-ws.org/Vol-1951/PrivOn2017_paper_6.pdf
[22] H. J. Pandit, C. Debruyne, D. O’Sullivan, and D. Lewis, “GConsent - A Consent Ontology Based on the GDPR,” in The Semantic Web, 2019, pp. 270–282 [Online]. Available: https://w3id.org/GConsent
[23] O. Sacco and A. Passant, “A Privacy Preference Ontology (PPO) for Linked Data.” in LDOW, 2011 [Online]. Available: http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.357.3591&rep=rep1&type=pdf. [Accessed: 08-Mar-2017]
[24] C. Bartolini and R. Muthuri, “Reconciling Data Protection Rights and Obligations: An Ontology of the Forthcoming EU Regulation,” in Workshop on Language and Semantic Technology for Legal Domain, 2015, p. 8.
[25] K. Fatema, E. Hadziselimovic, H. J. Pandit, C. Debruyne, D. Lewis, and D. O’Sullivan, “Compliance through Informed Consent: Semantic Based Consent Permission and Data Management Model,” in Proceedings of the 5th Workshop on Society, Privacy and the Semantic Web - Policy and Technology (PrivOn2017) (PrivOn), 2017 [Online]. Available: http://ceur-ws.org/Vol-1951/PrivOn2017_paper_5.pdf
[26] M. C. Suárez-Figueroa, A. Gómez-Pérez, and M. Fernández-López, “The NeOn Methodology for Ontology Engineering,” in Ontology Engineering in a Networked World, M. C. Suárez-Figueroa, A. Gómez-Pérez, E. Motta, and A. Gangemi, Eds. Berlin, Heidelberg: Springer Berlin Heidelberg, 2012, pp. 9–34 [Online]. Available: http://link.springer.com/10.1007/978-3-642-24794-1_2. [Accessed: 27-Nov-2017]
[27] R. J. Cronk, “CATEGORIES of personal information.” 01-Mar-2017 [Online]. Available: https://enterprivacy.com/2017/03/01/categories-of-personal-information/
[28] S. Kirrane et al., “SPECIAL deliverable d2.8 – transparency and compliance algorithms v2.” Nov-2018 [Online]. Available: https://www.specialprivacy.eu/images/documents/SPECIAL_D28_M23_V10.pdf
https://www.w3.org/community/dpvcg/wiki/Use-Cases,_Requirements,_Vocabularies↩︎
In hindsight, a better alternative was mapping languages such as R2RML https://www.w3.org/TR/r2rml/ for creating RDF data from spreadsheets.↩︎
https://ec.europa.eu/eurostat/ramon/nomenclatures/index.cfm?TargetUrl=LST_NOM_DTL&StrNom=NACE_REV2↩︎
https://en.wikipedia.org/wiki/Global_Industry_Classification_Standard#cite_note-mapbook-1↩︎
http://www.specialpricacy.eu↩︎