A Design Pattern Describing Use of Personal Data in Privacy Policies
Advances in Pattern-Based Ontology Engineering
✍ Harshvardhan J. Pandit* , Declan O'Sullivan , Dave Lewis
Description: Outlines an ontology design pattern for representing information associated with personal data in the context of a privacy policy
published version 🔓open-access archives: harshp.com
Information in Privacy Policies
A privacy policy provides disclosure of information regarding the collection, usage, storage, and sharing of personal data as governed by territorial laws [1], and is traditionally presented as a monolithic text document. A privacy policy can also contain relevant information such as the provision of rights, information about internal and external processes associated with privacy, legal obligations - with varying levels of complexity and comprehension. The European General Data Protection Regulation (GDPR) [2] defines obligations for provision of information to the individual regarding use and processing of their personal data - which in practice is commonly provided through privacy policies. This makes the analysis of privacy policies an essential component of legal compliance.
It has been repeatedly demonstrated that privacy policies are difficult to read and understand for the individuals [3]–[5]. In response, approaches have been developed towards making interpretation of privacy policies easier for end users such as ‘Terms of Service; Didn’t Read’1 - a community driven approach to summarise privacy policies in the interest of user. Other approaches have also been demonstrated utilising machine-learning to interpret contents of the privacy policy and presenting them in a visual and interactive format [6]–[8].
Given that privacy policies can be varied in both their medium and information, manual approaches can adapt to specifics of the policy but cannot scale with the ever-increasing and changing nature of services and their privacy policies. In contrast, automation can both adapt to the information in policies as well as scale its analysis of policies on the web. However automated approaches work only on a subset of the information and currently are not successful in interpreting the entirety of a privacy policy. Regulations such as the GDPR require specific information to be provided, thereby providing some commonality in content and its structure within the privacy policies. In addition, different policies tend to utilise the same structure and vocabulary as its regularises over time. This has resulted in a need for automated approaches to be augmented with manual annotations and verification by community and legal experts to increase the efficiency of information representation and extraction.
Automated approaches are based on interpreting textual information into a structured and machine-readable form that can be stored and analysed programmatically. To date, each automated approach has developed and utilised its own unique method and vocabulary to persist and analyse the information within privacy policies. This has resulted in duplication of both information and analysis, primarily due to a lack of annotated datasets - but also due to a lack of shared semantics and vocabulary. Sharing information extracted from privacy policies enables the creation of datasets that can be used to evaluate the effectiveness of approaches. Similarly, developing a common vocabulary will aid in the task of developing such datasets and comparing their results towards improving these approaches. In addition, such a common vocabulary also has applications in related domains such as legal compliance for expression and evaluation of information based on legal rules and obligations.
Using semantic web standards to express information provides a way to define knowledge in the form of concepts and relationships with the freedom for them to be expanded and connected based on requirements of the use-case and approach. The UsablePrivacy project already uses2 semantic web ontologies to represent its underlying information about the categorisation of sentences within a privacy policy [8]. Vocabularies exist to represent information associated with the GDPR [9], [10], user preferences regarding privacy [11], and taxonomies associated with legal compliance [12]. However, to date, no comprehensive ontology or schema exists that can annotate the contents of a privacy policy. While the lack of consensus on what information *is* present in a privacy policy continues, another part of the reason for this is the amount of information involved in a privacy policy and the relationships between them.
With this as the motivation, we present an ontology design pattern (ODP) for modelling the information related to personal data within a privacy policy. This ODP provides a way to express the personal data and the information associated with it as a set of concepts and relationships - in a manner which facilitates incorporation into a larger semantic web ontology. It also provides a strong argument and motivation towards development of a larger corpus and ontology for privacy policy where ODPs represent the different constituent parts that make up a privacy policy. Finally, the ODP provides a shared semantics for automated approaches regarding privacy policies to structure and represent their information, and facilitates the sharing of data and results between them.
This article expands upon the previous publication describing the ODP for personal data [13] to provide more information on application of the ODP. It also provides a more up-to-date discussion on the state of the art in terms of semantic vocabularies and future directions for this work. The rest of this article contains: description of the design pattern in [sec:pandit_personaldata_pattern], its application to a privacy policy in [sec:pandit_personaldata_example], discussion on recent state of the art and related work in [sec:pandit_personaldata_sota], and a conclusion discussing future work in [sec:pandit_personaldata_conclusion].
Pattern Description
Competency Questions for information regarding personal data
Information in a privacy policy regarding personal data usually consists of information relevant to the following queries which the pattern utilises as competency questions:
What personal data is collected? e.g. email
Does the data have a category? e.g. contact information
What was its source? e.g. user
How is it collected? e.g. given by user, automated
What is it used for? e.g. creating an account, authentication and verification
How long is it retained for? e.g. 90 days after account deletion
Who is it shared with? e.g. name of partner organisation(s)
What is the legal basis? e.g. given consent, legitimate use
What processes/purposes was the data shared for? e.g. analytics, marketing
What is the legal type of third party? e.g. processor, controller, authority
In addition, other relevant questions also exist - such as those related to the provision of (GDPR) rights and the use of technologies. While these questions are relevant, they are directly related to the individual or to the service, and thus are common to all instances of personal data. They are therefore better represented separately within a privacy policy design pattern or ontology which can be selectively associated with personal data. We provide them here for brevity with a further discussion on this provided for future work in [sec:pandit_personaldata_conclusion]:
How can personal data be rectified or corrected?
How can personal data be deleted or removed?
How can a copy of the personal data be obtained?
How can personal data be transferred to another party?
How can information about the personal data be obtained?
What measures exist to safeguard personal data?
Follow-up queries in response to these questions can also be considered within the scope of a privacy policy. Examples include technical implementation details such as levels of encryption, processing technologies such as cloud servers and their location, use of automation and profiling. While this information is also relevant to the use of personal data and its description in a privacy policy, it can be considered ‘secondary’ based on its optional existence as well as commonality between different categories of personal data and processing - similar to information about rights and technical measures.
Representing Concepts & Relationships
While a design pattern usually does not use external vocabularies (except standardised ones) in order to provide an ‘abstract implementation’, we describe our pattern using the GDPRtEXT[10] and GDPRov[9] ontologies that provide concepts relevant to the GDPR. GDPRtEXT provides definitions of concepts and terms used within the text of the GDPR using SKOS. GDPRov is an ontology for describing the provenance of consent and personal data life-cycles using GDPR relevant terminology, and is an extension of PROV-O and P-Plan. Though it is possible to define the pattern using new abstract concepts, we reuse existing concepts and properties where applicable in the interest of practical applicability. The abstract pattern can be created as an ontology and legislation independent implementation by extracting the concepts and relationships into an empty namespace.
The pattern is described here in terms of its concepts and relationships. A visualisation of the pattern is presented in [fig:pandit_personaldata_fullpattern] - created using yEd3 and using with the Graffoo4 [14] specification for diagrammatic representation of ontologies. The pattern is available online along with its documentation5 and has been submitted to the ontology design patterns collaborative wiki6.
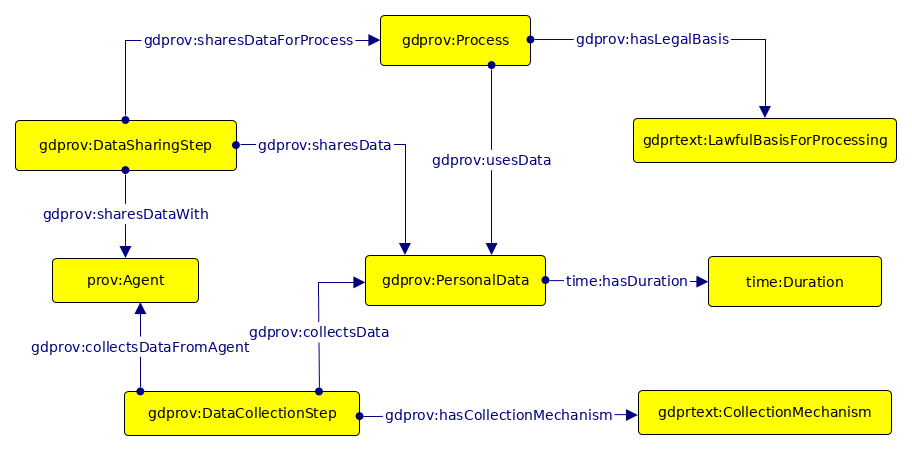
Personal Data
PersonalData represents an instance of personal data, such as an email address, which is described in the privacy policy. It is defined as an instance of gdprov:PersonalData. Privacy policies often group related instances of personal data in broader categories - such as contact information for representing email and phone number. To represent such a grouping in the pattern, the category can be represented as a subclass of PersonalData using rdfs:subClassOf, with its instances representing individual personal data items. In this case, contact information would be a subclass of gdprov:PersonalData with email and phone number being its instances. PersonalDataCategory ⊑ PersonalData
Source of Data
The source of personal data depicts where the data is obtained or collected. This is described using the dct:source property with the range defined as an instance of gdprtext:Entity, or its subclasses such as User or ThirdParty. Since every personal data must have at least one source, this provides the axiom: PersonalData ⊑ ≥ 1source.Entity
Data Collection
Data is collected through a gdprov:DataCollectionStep, and is represented using the property gdprov:collectsData. The data provider is represented using prov:Agent through the property gdprov:collectsDataFromAgent.
Apart from the source, the privacy policy may also mention the particular collection mechanism used for data collection. This is represented using the gdprov:hasCollectionMechanism property, where the collection mechanism is represented by a suitable subclass of gdprtext:CollectionMechanism, such as gdprtext:GivenByUser or gdprtext:AutomatedCollection. DataCollectionStep ⊑ ≥ 1collectsData.PersonalData DataCollectionStep ⊑ ≥ 1collectsDataFromAgent.Agent PersonalData ⊑ ∀hasCollectionMechanism.CollectionMechanism
Data Retention
The retention of personal data informs how long it would be stored for. This is represented using the Time Ontology in OWL7, which is the W3C recommendation for describing temporal concepts. The retention period is represented using the property time:hasDuration with the range being an instance of time:Duration. This information is arbitrary and may be missing or in a non-representable format within the privacy policy such as “retained for as long as necessary” where the information is difficult to represent. PersonalData ⊑ ∀hasDuration.Duration
Data Usage & Processing
Data Usage, also termed as Processing, is the use of personal data for some purpose as specified within the privacy policy. This can vary in terms of granularity from a comparatively simple step such as sending an email to a more abstract process such as marketing which encompasses several steps and processes. The pattern therefore uses gdprov:Process, which is a subclass of p-plan:Plan, to define a process which can contain one or more steps and processes. The property gdprov:usesData is used to represent the use of personal data within a process. Process ⊑ ≥ 1usesData.PersonalData
Legal Basis for Data Usage
Every use of personal data within a process must have a legal basis under the GDPR. Examples of such legal basis defined within GDPRtEXT include consent, legitimate interest, compliance with the law, and performance of contract. To represent this, the pattern uses the property gdprov:hasLegalBasis with the range gdprtext:LawfulBasisForProcessing. Since every data use must have at least one legal basis, this provides the axiom: Process ⊑ ≥ 1hasLegalBasis.LawfulBasisForProcessing
Data Sharing
The sharing of data involves the entity the data is shared with, the purposes for sharing, and their legal basis. This is represented within the pattern through the use of gdprov:DataSharingStep and the property gdprov:sharesData. The entity the data is shared with is represented using the gdprov:sharesDataWith property with the domain as gdprov:DataSharingStep and the range as a type of gdprov:Agent, such as another Data Controller, Data Processor, or an Authority. The purpose of sharing is represented using gdprov:Process and the property gdprov:sharesDataForProcess to model the data being used in that process after sharing. The legal basis of processes for which the data is shared is represented using gdprov:hasLegalBasis as specified earlier. Since it is mandatory to inform who the data is being shared with, along with its intended purposes, and the specific legal obligation, we have the following axioms: DataSharingStep ⊑ ≥ 1sharesData.PersonalData DataSharingStep ⊑ ≥ 1sharesDataWith.Agent DataSharingStep ⊑ ≥ 1sharesDataFor.Process
Example Use-Case
We present here an example use-case of the pattern for depicting information regarding personal data from Airbnb Ireland’s privacy policy8 with archived copies made available9 in case of changes to the policy in future. The use-case was chosen for its generality in terms of being common to other privacy policies as well as ease of understanding for users. While we also evaluated other privacy policies for their structure and content, we chose this example as our primary use-case for the purpose of this work due to its relative transparency and convenient structuring of information. An outlook into how information within the privacy policy provided by Airbnb Ireland was analysed and interpreted is available online10 - though it is not directly relevant to the presented example.
The use-case concerns ‘email address’ specified as personal data within the privacy policy, which is provided by the user. It is used to “provide, improve, and develop platform services”, which is specified as a process with the legal basis of legitimate interest. It is shared with the ‘Payments Controller’ entity for ‘Identity Verification’ process which has a legal basis of ’contract fulfilment’.
The example use-case is illustrated in Fig. [fig:pandit_personaldata_use-case] using Graffoo [14] and shows the classes, properties, and instances. The corresponding code is presented in the following listing using the Turtle11 notation for RDF.
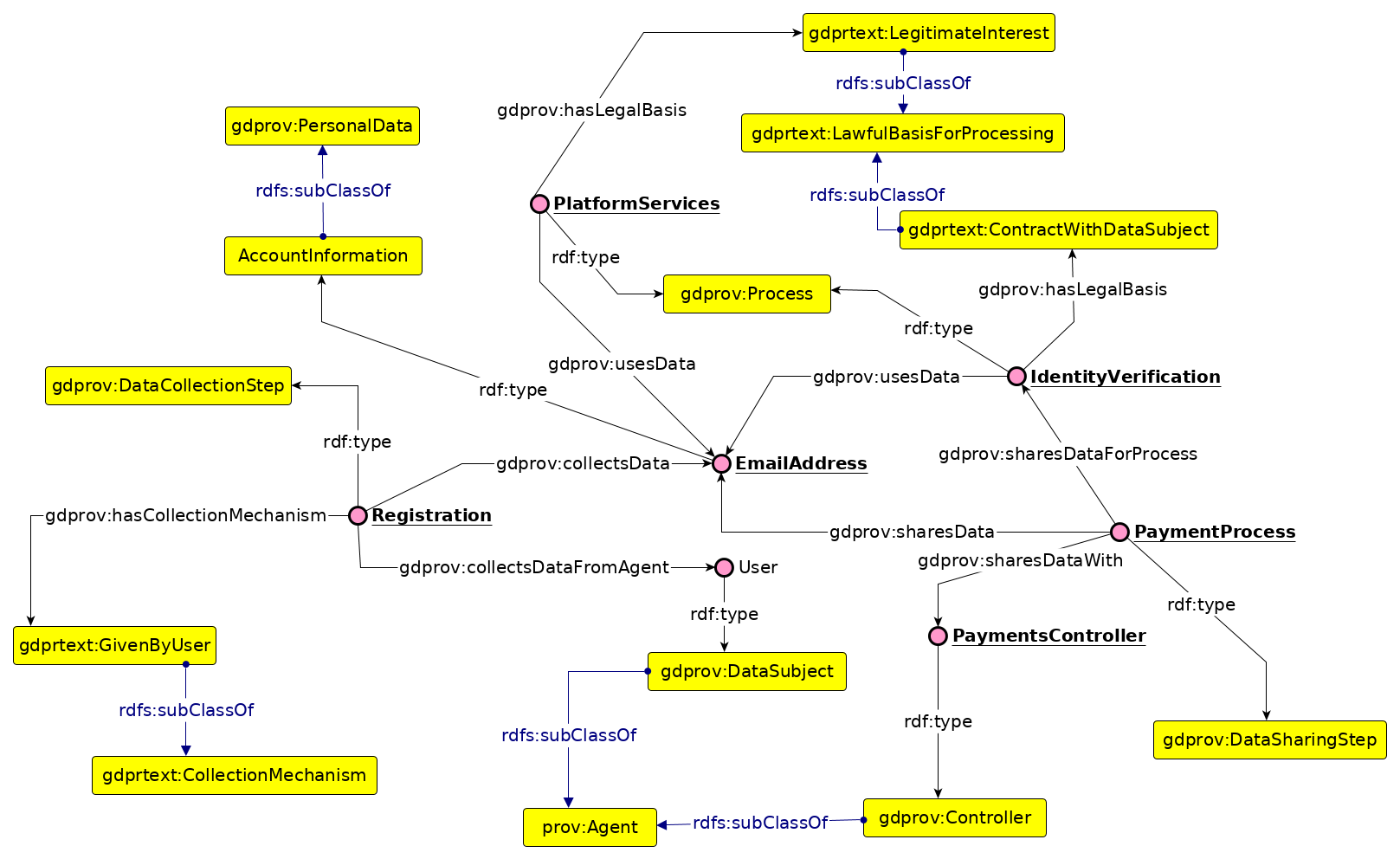
@prefix dct: <http://purl.org/dc/terms/> .
@prefix owl: <http://www.w3.org/2002/07/owl#> .
@prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> .
@prefix rdfs: <http://www.w3.org/2000/01/rdf-schema#> .
@prefix xml: <http://www.w3.org/XML/1998/namespace> .
@prefix xsd: <http://www.w3.org/2001/XMLSchema#> .
@prefix gdprov:
<http://purl.org/adaptcentre/openscience/ontologies/gdprov#> .
@prefix gdprtext:
<http://purl.org/adaptcentre/openscience/ontologies/GDPRtEXT#> .
@prefix : <http://example.com/personaldata#> .
:PaymentProcess a gdprov:DataSharingStep ;
rdfs:label "Payment Process"^^xsd:string ;
gdprov:sharesData :EmailAddress ;
gdprov:sharesDataForProcess :IdentityVerification ;
gdprov:sharesDataWith :PaymentsController .
:PlatformServices a gdprov:Process ;
rdfs:label "Provide, Improve, and Develop Platform"^^xsd:string ;
gdprov:hasLegalBasis gdprtext:LegitimateInterest ;
gdprov:usesData :EmailAddress .
:Registration a gdprov:DataCollectionStep ;
rdfs:label "Registration for new users"^^xsd:string ;
gdprov:collectsData :EmailAddress ;
gdprov:collectsDataFromAgent :User ;
gdprov:hasCollectionMechanism gdprtext:GivenByUser .
:AccountInformation a rdfs:Class, owl:Class ;
rdfs:label "Account Information of an User"^^xsd:string ;
rdfs:subClassOf gdprov:PersonalData .
:IdentityVerification a gdprov:Process ;
rdfs:label "Identity Verification"^^xsd:string ;
gdprov:hasLegalBasis gdprtext:Contract ;
gdprov:usesData :EmailAddress .
:PaymentsController a gdprov:Controller,
prov:Agent ;
rdfs:label "Payments Controller"^^xsd:string .
:User a gdprov:DataSubject,
prov:Agent ;
rdfs:label "User of Service"^^xsd:string .
:EmailAddress a :AccountInformation,
:PersonalData ;
rdfs:label "Email Address"^^xsd:string .The answers to the competency questions corresponding to the use-case are provided below. The RDF code has been truncated by removing annotation properties to save space. The example in its entirety is available online12.
What personal data is collected: Email Address
Does the data have a category: Account Information
What was its source: User
How is it collected: Given by user
What is it used for: Platform Services, Payments
How long is it retained for: indefinitely (no end duration)
Who is it shared with: Payments Controller
What is the legal basis: Legitimate Interest, Contract
What processes/purposes was the data shared for: Identity Verification
What is the legal type of third party: Data Controller
Discussion: Application to State of the Art
The generation of privacy policy corpus and datasets continues with time owing to the change in laws, content, and new methods of investigation. Recent advances in this field include PrivacySeer [15] - which analysed a large corpus of policies to distinguish first and third party sharing, use of cookies and tracking, and specific provisions for European audiences. Another approach, MAPS [16], evaluates privacy policies associated with smart-phone applications with a particular focus on contextual data such as location and connectivity information.
CLAUDETTE [17] discusses creation of a gold standard based on information presence and requirements, and highlights challenges regarding context of information (e.g. at a sentence level) and omission of information. Degelin et al. [18] also analyse privacy policies and reiterate multilingualism as a challenge. Amos et al. [19] have recently published a corpus consisting of over a million policies and their iterations over two decades. In addition to the data being available for reuse, the corpus marks the largest dataset of policies currently available.
Simultaneous to the corpus generation, its users - including the ones mentioned earlier - have not yet considered creation of a common schema or structure for the information they analyse. Some examples of this include an approach for question answering over privacy policies [20] which has produced 1750 questions and 3500 expert annotations of answers over policies, but has not provided motivation on the structuring of information. Similarly, Morel et al. analyse privacy policies [21] and discuss the role of semantics and available avenues across semantic technologies but do not mention creation of a contextual ontology suitable for the task. Bhatia et al. [22] discuss semantic roles in context of the information in a privacy policy and its relationship to decisions and risks, but stop short of suggesting an ontological approach.
Conversely, other approaches that do model the relevant semantics do not apply it to privacy policies. These include approaches that model privacy and/or data protection concepts - such as GDPRtEXt [10] and GDPRov [9]; and also approaches that model preferences such as the Privacy Preference Ontology [11]. A notable addition to these is the Data Privacy Vocabulary13 (DPV) [12], which is a vocabulary providing a taxonomy of concepts associated with use and processing of personal data, and an outcome of the W3C Data Privacy Vocabularies and Controls Community Group.
With these, it is clear that on one hand are approaches for automation utilising machine-learning and natural-language processing to extract and analyse information from privacy policies, and on the other hand are approaches that model information relevant to privacy and data protection. Through this ODP, we hope to encourage the two approaches to interleave and produce an annotated corpus that utilises semantics to share and reuse information. In this, the ODP is useful in automation by representing the ‘core’ information currently utilised in analysis of privacy policies, while also encouraging the ontological approaches to develop a more comprehensive representation of privacy policies.
Conclusion
This article presented an ontology design pattern for representing information associated with personal data in the context of a privacy policy. More specifically, it allows modelling and representation of collection, usage, storage, and sharing of personal data along with the associated processes and entities, as well as their legal basis. Concepts and relationships within the pattern are defined using the previously published GDPRov [9] and GDPRtEXT [10] ontologies. For defining the duration of storage, the pattern uses the Time ontology in OWL.
The application and suitability of the pattern is demonstrated through the use-case based on an real-world privacy policy. It shows that the ODP captures common queries regarding personal data, and that it is useful as a common representation for related activities such as summarising, visualisation, analytics, or determining compliance using information contained within privacy policies. It simultaneously motivates the development of other related ODPs relevant to the information presented in a privacy policy.
Based on the motivation we started with, and a discussion on the relevance of our work with the state of the art, we conclude that the ODP presented in this article provides a way to represent and share relevant information regarding personal data, and provides further avenues for research and development of similar patterns or meta-patterns related to privacy policies. At the very least, the pattern demonstrates the possibility to model information in a privacy policy in a structured format that can be incorporated into larger ontologies and approaches as required.
Future Work
We consider our work on this ODP as an initial effort towards consolidating information within privacy policies. Using the pattern to reflect information from several distinct real-world privacy policies will demonstrate its feasibility and applicability in real-world scenarios. This presents a challenge as the pattern currently assumes the presence of all required information which may not be the case for some use-cases, particularly where interpretations of information are ambiguous. However, capturing such ambiguities through a meta-pattern can possibly aid in flagging them for review by legal experts.
In addition to the above, the pattern faces other challenges for the modelling of information it aims to represent. For example, it is not clear what level of abstraction should be represented in the pattern regarding concepts such as storage and sharing. Should there be a DataStorageStep which can be further annotated to represent various pieces of information relating to the storage of personal data? Abstractions can help to represent different storage duration and formats for the same instance of personal data, such as storing the actual data for 6 months while a (pseudo-)anonymised copy is stored for 2 years. However, tacking on such abstractions in to the pattern can make it rigid (in terms of modelling) and complex. More work needs to be undertaken to evaluate whether such abstractions are necessary in the pattern, and how they should be represented.
Another challenge is the representation of storage duration (or retention period). Concrete values such as 6 months or 2 years can be represented using appropriate ontologies, but ambiguous statements are difficult to represent using such ontologies. An example of this is the statement "data may be stored for as long as necessary..." in which there is no end to the duration for storage. Representing this as a time:Duration instance is problematic as there is no clear method to represent its end period. Not defining an end period is also not a solution due to the open world assumption. Our approach towards solving this issue is to abstract the storage activity as described earlier. However, we are open for other approaches and solutions towards this problem.
The privacy policy contains more information than is reflected by the pattern. To represent this additional set(s) of information, larger (combinations of) patterns and ontologies will be needed to model and represent all the relevant information and context. This is especially relevant for GDPR as it mandates the inclusion of information regarding its various rights, which is presented through the privacy policy. Some of this information was presented as additional competency questions, either due to its common relation at the policy level or due to its secondary nature in connection with the personal data.
Capturing this information is essential towards quantifying the privacy policies into machine-readable data, with the paper demonstrating the suitability of ODPs for this task. This motivates creation of granular, context-specific ODPs regarding privacy policies which can represent information regarding concepts such as rights and technical measures, and which can be used in the existing implementations of automated analyses and information extraction approaches.
Acknowledgements
This work is supported by the ADAPT Centre for Digital Content Technology which is funded under the SFI Research Centres Programme (Grant 13/RC/2106) and is co-funded under the European Regional Development Fund.
References
The UsablePrivacy project provides a dataset of tagged privacy policies, which has been utilised by most of the other approaches. However, this dataset lacks a formal vocabulary describing its contents, and is out-of-date compared with the privacy policies of today.↩︎
https://openscience.adaptcentre.ie/projects/privacy-policy/design-pattern/↩︎
http://ontologydesignpatterns.org/wiki/Submissions:PrivacyPolicyPersonalData↩︎
https://opengogs.adaptcentre.ie/harsh/privacy-policy-dashboard/↩︎
http://openscience.adaptcentre.ie/privacy-policy/personalise/demo/policy.html↩︎
https://openscience.adaptcentre.ie/ontologies/design-pattern-eg.ttl↩︎